Struktur von Google™ Earth
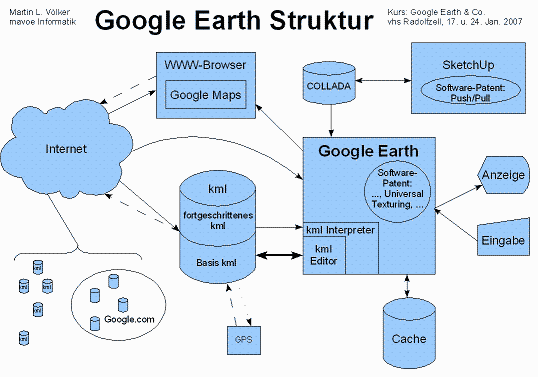
- Die folgende Grafik zeigt, wie ich die Struktur von Google™ Earth im Frühjahr 2008 sah.
- Der folgende Text ist meine Übersetzung des englischen Artikels auf der www-Seite
http://www.realityprime.com/articles/how-google-earth-really-works
(ohne der dort gemachten Kommentare)
(Es gibt auch eine japanische Übersetzung dieses Artikels (allerdings ohne die Zustimmung von Avi Bar-Zeev)).Wie Google Earth [Wirklich] Funktioniert
Veröffentlicht am 3. Juli 2007 von aviEinleitung
Nachdem ich auf der großartigen Website HowStuffWorks.com den Artikel "Wie Google Earth Funktioniert" gelesen hatte, wurde mir klar, daß dieser Artikel eher ein "cool, wie es ist" und ein "hier ist, wie's benutzt wird" war, als ein "wie Google Earth [wirklich] funktioniert".
Also dachte ich, es wäre vielleicht interessant und trotz einigem zu beachtendem geistigen Eigentums - hier ist er "Teil Eins" der Erklärung, wie zumindest ein Teil von Google Earth funktioniert.
Denkt daran, die Frage des geistigen Eigentums ist real. Keyhole (jetzt bekannt als Google Earth) wurde schon einmal angegriffen mit der Behauptung, daß sie die minderwertige (IMO) Technologie eines anderen kopiert hätten. Die Klage wurde von einem Richter vollständig abgewiesen, aber erst nach vielen, schmerzvollen Jahren. Das zeigt immer noch, wie schwierig es ist, alleine über diesen Stoff zu reden. Alles was man sagt, könnte Futter für so einen Troll sein, zu behaupten er hätte das erfunden, nur weil das, was du erfandest, "ähnlich klingt". Der Richter im Fall Skyline / Google verstand, daß "ähnlich klingende" nicht genug ist, um eine Zuwiderhandlung zu beweisen. Das tun nicht alle Richter.
Wie dem auch sei, die Lösung, um über "Wie Google Earth [Wirklich] Funktioniert" zu diskutieren, ist, bei den Informationen zu bleiben, die bereits in verschiedenen Formen bekannt gemacht worden sind, besonders in Googles eigenen Patenten, von denen es verhältnismäßig wenige gibt. Weniger Software-Patente ist besser für die Welt. Aber in diesem Fall, würden mehr Patente bedeuten, dass wir über die Technologie offener sprechen könnten, was, nebenbei, eins der ursprünglichen Ziele von Patenten war - ein Handel in dem begrenzte Monopolrechte einem echten, öffentlichen Vorteil gegenüber stehen: der Bekanntgabe. Aber ich schweife ab …
Für die eher technisch gestrickten, Du möchtest diese Patente vielleicht direkt lesen. Sei gewarnt: Rechtsanwälte und Technologen emulgieren manchmal, um eine Art linguistische Majonäse zu bilden, eine, die Seele abstumpfende Substanz, bekannt als Patent-Englisch, oder kurz Painglish. Wenn Du mutig oder masochistisch bist, los geht's:
1. Asynchronous Multilevel Textur-Pipeline
2. Server for geospatially organized flat file dataEs gibt auch ein paar eher nebenbei betroffene Google-Patente. Ich weiß nicht, warum diese schreien, aber vielleicht, weil sie auf ihrem Gebiet sehr wichtig sind. Ich werde hoffentlich in zukünftigen Artikeln auf diese ausführlicher zurück kommen:
3. DIGITAL MAPPING SYSTEM
4. GENERATING AND SERVING TILES IN A DIGITAL MAPPING SYSTEM
5. DETERMINING ADVERTISEMENTS USING USER INTEREST INFORMATION AND MAP-BASED LOCATION INFORMATION
6. ENTITY DISPLAY PRIORITY IN A DISTRIBUTED GEOGRAPHIC INFORMATION SYSTEM (dieses ist riesig)Und es gibt dieses informativere, technische Referat von SGI (pdf) über Hardware "clipmapping", auf das wir uns später beziehen werden. Nebenbei Michael Jones ist eine der treibenden Kräfte hinter Google Earth und als CTO, fördert er nach wie vor diese Technologie.
Ich werde mich an das halten, was veröffentlicht wurde oder sonst wie allgemein technisches Wissen ist. Aber ich erklären es hoffentlich so, daß die meisten Menschen es verstehen können und vielleicht sogar schätzen. Zumindest ist das mein Ziel. Last es mich wissen.
Große Einschränkung: Die Google-Earth-Code-Basis wurde wahrscheinlich bereits mehrmals umgeschrieben, seitdem ich bei Keyhole etwas damit zu tun hatte und vielleicht auch nachdem diese Patente eingereicht wurden. Es genügt zu sagen, das die neuesten Implementierungen sich erheblich verändert haben können Und meine Erklärungen sollen so breit werden (und sind möglicherweise so veraltet), daß niemand diesen Artikel als Grundlage für irgend etwas anderes als für intellektuelle Neugier und Verständnis nehmen soll.
Weitere Anmerkung: Wir werden umgekehrt vorgehen, so seltsam es auch scheinen mag, beginnend mit dem Zustand im dem die 3D-Erde auf Deinen Bildschirm gezeichnet wird und später zu dem Ursprung der Daten zurück kehren. Ich glaube, dass dieses hilft, zu erklären, warum die Dinge so getan wurden, wie sie getan wurden und warum einige andere Ansätze nicht annähernd so gut funktionieren.
Teil 1, Das Ergebnis: Einen Virtuellen 3D-Globus Zeichnen
Es gibt zwei grundsätzliche Unterschiede zwischen Google Maps und Earth, die zeigen, wie die Sachen unter der Haube idealer weise arbeiten sollten. Der erste ist der Unterschied zwischen fester 2D-Ansicht (meist von oben) und freiem, perspektivischem 3D-Rendering. Der zweite ist der zwischen Echtzeit- und vor-gerenderten Grafiken. Diese zwei Unterscheidungen nehmen ab, während die Produkte verbessert und ähnlicher werden. Aber sie markieren wichtige Unterschiede, auch heute noch.
Was beide gemeinsam haben, ist, daß sie mit herkömmlichen digitalen Fotos beginnen - vielen davon - im Grunde ein riesiges, hoch auflösendes (oder unterschiedlich auflösendes) Bild der Erde. Worin sie sich hauptsächlich unterscheiden, ist, wie sie die Daten rendern.
Beachte: Die Erde hat ungefähr 40.000 Kilometer um die Taille. Wer sagt, es ist eine kleine Welt, ist kindisch. Wenn Du für jeden Quadratkilometer Oberfläche nur ein Pixel Farb-Information speicherst, dann wäre das ganze Erde-Bild (flach gedrückt in, sagen wir, eine Mercator-Projektion) etwa 40.000 Pixel breit und etwa halb so hoch. Das ist weit mehr als die meiste 3D-Grafik-Hardware heute verarbeiten kann. Wir sprechen über ein Bild mit 800 Megapixels und mindestens 2,4 Gigabyte . Heute haben viele PCs noch nicht einmal 2 GB Hauptspeicher. Und was den Video Speicher angeht, der für das Rendern benötigt wird, hat ein typischer PC vielleicht 128 MB und eine High-End-Gaming-Kiste gerade mal über 512.
Denke daran, daß das nur Dein grundlegendes ein-Kilometer-pro-Pixel Bild der ganzen Erde ist. Der kleinste Gegenstand, der auf solch einem Bild aus zu machen ist, ist etwa 2 km breit (Danke, Herr Nyquist) - es wären keine Gebäude, Flüsse, Straßen, oder Menschen zu erkennen. Aber für die meisten größeren Städten der USA, bietet Google Earth eine Auflösung, die Objekte, die einen halben Meter oder kleiner sind, erkennbar macht. Das ist mindestens vier tausend mal dichter, oder sechzehn Millionen Mal mehr Speicherplatz als das obige Beispiel.
Wir reden über Bilder, die buchstäblich viele Terabytes Speicher bräuchten (und brauchen). Es gibt keine Möglichkeit, daß solch ein Ding auf heutige PCs überhaupt gezeichnet werden könnte, vor allem nicht in Echtzeit.
Und doch geschieht es jedes Mal, wenn Du Google Earth laufen läßt.
Beachte: In einem echten, virtuelle 3D-Globus, kannst Du Deine Ansicht beliebig neigen und drehen, um nahezu überall hin zu schauen (außer unter die Oberfläche - und auch das ist möglich, wenn wir die Daten haben). In allen 3D-Globen gibt es grundlegende Daten, in der Regel ein wirklich hoch auflösendes Bild der Oberfläche der ganzen Erde oder zumindest der Teile, für die die Firma Daten gekauft hat. Diese grundlegenden Daten müssen an Deinen Monitor geliefert werden sowie auf irgend einen virtuellen Kugelausschnitt oder idealerweise auf kleine 3D-Oberflächen (Dreiecke, etc…) abgebildet werden, die das reale Gelände, Berge, Flüsse usw. nachahmen.
Wenn Du als Software-Designer entscheidest, weder das Kippen noch das Dreher Deiner Ansicht der Erde zuzulassen, dann, Glückwunsch, hast Du das Engineering-Problem vereinfachte und kannst ein bisschen frei nehmen. Aber andererseits hast Du dann nicht Google Earth.
Nun existieren verschiedene Entwürfe, die einem erlauben, einen Teil dieser lächerlich großen Textur zu durchwandern. Andere Mapping-Anwendungen lösen dies auf ihre eigene Art und oft mit erheblichen Einschränkungen oder visuellen Artefakten. Die meisten von ihnen schneiden einfach ihre riesige Erde in kleine regelmäßige Kacheln, möglicherweise in einem Quadtree angeordnet und zeichnen immer wieder einige dieser Kacheln auf Deinen Schirm, entweder in 2D (wie Google Maps) oder in 3D, wie Microsofts Virtual Earth es anscheinend tut.
Aber die Art und Weise wie Google Earth das Problem gelöst hat, war wirklich neu und ein Software-Patent wert (und ich bin generell gegen Software-Patente). Um sie zu erklären, müssen wir einige Kernkonzepte aufbauen. Etwas Hintergrund in digitaler Signal-Theorie und Computergrafik schadet nie, aber ich hoffe, es wird einfach genug, daß das nicht nötig ist.
Ich werde nicht erklären, wie 3D Rendering funktioniert - daß gibt's wo anders. Aber ich werde mich auf Textur-Mapping und insbesondere Textur-Filterung konzentrieren, weil diese Details lebenswichtig für die Arbeit sind. Die Vorgehensweise von den grundlegenden Konzepten hin zur fortgeschrittenen Textur-Filterung wird auch Dir helfen, zu verstehen, warum die Dinge auf dieser Art und Weise funktionieren und wie erstaunlich diese Technologie tatsächlich ist. Wenn Du Geduld hast, bekommst Du hier eine sehr schnelle Lektion in Textur-Filterung.
Die Grundlagen
Das Problem des Skalierens, Drehens und Verzerrens von einfachen 2D-Bilder wurde vor langer Zeit gelöst. Die übliche Lösung heißt Bilinear Filterung. Dabei kommt es darauf an, daß Du für jedes neue (gedrehte, skalierte, etc..) Pixel, das Du berechnen willst, die vier "besten" Pixel aus dem Originalbild nimmst und zusammen mischst. Es ist "bilinear", weil es für die endgültige Antwort zuerst zwei Pixel linear mischt (entlang einer Achse) und dann wiederum diese beiden Ergebnisse linear mischt (entlang der anderen Achse).
[Eine "lineare Mischung", für den Fall, daß das nicht klar ist, ist irre einfach: Nehme 40% der Farbe A, und 60% der Farbe B und addiere sie zusammen. Die Aufteilung 40/60 ist unterschiedlich, je nachdem, wie "wichtig" jeder Beitrag ist, solange die Summe 100% ergibt.]
Diese Funktionalität ist in Deine 3D-Grafik-Hardware eingebaut, so daß Dein Computer heutzutage buchstäblich Milliarden von diesen Berechnungen pro Sekunde machen kann. Frage mich nicht, warum Dein bevorzugtes Mal-Programm so langsam ist.
Das Problem, auf das es ankommt, kann recht leicht sichtbar gemacht werden - das ist, was ich an Computergrafik liebe. Es wird sichtbar, immer wenn wir einige Quell-Pixel auf geänderte (gedrehte, skalierte, gekippte, etc…) Ziel-Pixel abbilden - visuelle Information geht verloren.
Das Problem heißt "Aliasing" und es tritt auf, weil wir beim Digitalisieren das Originalbild auf eine Art und mit einer bestimmten Frequenz (alias Auflösung) aufbauten und jetzt bauen wir dieses Bild auf eine etwas andere Art erneut auf, was nicht gut zusammen paßt.

1. Ein einfaches (11 x 11 Pixel) Bild, mit niedriger Auflösung soll gedreht werden. (die Gitterlinien dienen dazu, die Pixel abzugrenzen))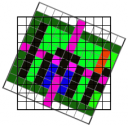
2. Jedes Pixel im Ziel-Raster überschneidet mehrfache Pixel des gedrehten Originals.
3. Nahaufnahme eines Ziel-Pixels. Bilineare Interpolation bildet für jedes neue Ziel-Pixel (gezeigt als schwarzer Rand mit weißen Punkten) den Durchschnitt aus den "besten" vier Quell-Pixeln basierend auf ihrer relativen Bedeutung (Idealfall: minimale Fläche).
4. Nach der Bilinearen Interpolation hat das sich ergebende, gedrehte Bild eine klare (oder eher verschwommen) Ausgabe.Wenn wir jetzt über Ausgangs-Pixel und Bestimmungsorte sprechen, macht es nicht viel aus, ob das Ziel eine Bitmap in einem Mal-Programm ist oder ein Fenster einer 3D-Anwendung, das die Erde zeigt. Aliasing passiert immer dann, wenn sich die Ausgabe-Pixel nicht mit dem Raster (Frequenz, Auflösung) des Quell-Bilde decken. Und Aliasing steht für ein schwaches visuelles Ergebnis. Der Umgang mit Aliasing ist etwa die Hälfte von dem, worum es bei Textur-Mapping geht. Der Rest ist meist Speicherverwaltung. Und aus den Zwänge zwischen beiden ergibt sich, wie Google Earth funktioniert.
Der Auftrag ist also, Aliasing durch Geschicklichkeit und gutes Design zu minimieren. Der beste Weg, dies zu tun ist, möglichst nahe an eine 1:1 Entsprechung zwischen Quell- und Ziel-Pickeln zu kommen oder zumindest so viele zusätzliche Pixel zu generieren, daß wir die Auflösung es Ziel-Bildes wieder verkleinern und so das Aliasing sicher minimieren können. (auch bekannt als "Anti-Aliasing"). Wir machen oft beides.
Beachte: Größenänderungen von Bildern, machen es nur noch schlimmer - jedes Pixel in Deinem Ziel-Bild kann Hunderten von Pixeln des Quell- Bildes entsprechen, und umgekehrt. Bilineare Interpolation, erinnere Dich, nimmt nur die besten vier Quell-Pixel und ignoriert den Rest. Es kann also daher wichtige Pixels, wie Kanten, Schatten, oder Reflexionen einfach überspringen. Wenn irgend ein solches Pixel während einer Berechnung beim Mischen berücksichtigt wird und danach nicht mehr, erhältst Du ein häßliches "Pixel-Springen" oder einen Verwisch-Effekt. Ich bin sicher, daß Du das in einigen Videospielen gesehen hast. Nun weißt Du, warum.
Ein Kipp-Bild (oder jede 3D-Transformation) ist sogar noch problematischer, denn jetzt haben wir neben Skalieren und Rotieren auch noch große Veränderungen der Pixel-Dichte innerhalb der gerenderten Oberflächen. Z.B. kann im "nahen" Teil einer Szene, Dein nett hoch aufgelöstes Bild der Oberfläche so sehr vergrößert werden, dass die Pixel ganz verschwommen aussehen. Im "weiten" Teil der Szene, könnte Dein Bild verwischt aussehen (wie oben) weil einfache 2 x 2 bilinear Interpolation notwendigerweise wichtige Bild-Details gelegentlich überspringt.
 Copyright, Microsoft Virtual Earth
Copyright, Microsoft Virtual Earth
Hier ein Beispiel, wie eine bestimmte Art von Textur-Filterung ein schlechtes Ergebnisse verursacht. Die Text-Etiketten sind kaum lesbar (warum sie überhaupt in das Gelände-Bild gemalt sind, ist ein anderes Thema).Bessere Filterung, Enthüllung
Die meiste Konsumer-3D-Hardware unterstützt bereits, was "tri-lineare" Filterung genannt wird. Mit tri-linear und einer nah verwandten Technik namens MIP-Mapping, berechnet und speichert die Hardware eine Reihe Versionen mit geringerer Auflösung Deines Quell-Bildes oder Deiner Textur. Jede MIP-Map wird automatisch um den Faktor 2 gröber, so oft, bis wir ein 1 x 1 Pixel-Bild erreichen, dessen Farbe der Durchschnitt aller Quell-Bild-Pixel ist.
Also, wenn Du zum Beispiel die Hardware mit einem netten 512 x 512 Quell-Bild versorgst, würde sie 8 extra MIP-Levels für Dich berechnen und speichern (256, 128, 64, 32, 16, 8, 4, 2 und 1 Pixel-Quadrat). Wenn Du die vertikal stapelst, kannst du den "MIP-Stack" leichter als auf dem Kopf stehende Pyramide sichtbar machen, in der jedes MIP-Level (jede horizontale Schicht) immer 1/2 so breite wie die darüber ist.
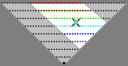 Zeichnung einer MIP-Map-
Zeichnung einer MIP-Map-
Pyramide (nicht maßstabsgetreu).
Das x stellt die tri-lineare Filter-Berechnung dar für ein Zwischen-Pixel, um Aliasing zu verringert.Während des 3D-Renderns nehmen Mip-Mapping und tri-lineare Filterung jedes Ziel-Pixel, wählen dafür die beiden am besten geeignete Mip-Ebenen aus, führen im Wesentlichen eine bi-lineare Mischung für beide aus, und mischen dann diese beiden Ergebnisse wieder (linear) für die abschließende tri-lineare Antwort.
Sagen wir zum Beispiel das nächsten Pixel hätte kein Aliasing, wenn das Quell-Bild nur eine Auflösung von 47,5 Pixel in der Breite hätte. Das System hat 2er-Potenzen-Mip-Maps gespeichert (16, 32, 64…). So benutzt die Hardware geschickt die 64x64 und 32x32 Pixel Versionen, die der gewünschten Auflösung von 47,5 am Nächsten kommen, berechnet die bilinearen Ergebnisse (4-Samples) für jede und nimmt dann diese beiden Ergebnisse und mischt sie ein drittes Mal.
Das ist tri-linear-Filterung in kurzen Worten, und zusammen mit Mip-Mapping überwindet es für viele gängige Fälle von 3D-Transformationen eine große Stecke auf dem Weg Aliasing zu minimieren.
Erinnere Dich: bis jetzt haben wir über nette, kleine Bilder mit z.B. 512x512 Pixels gesprochen. Unsere Bild der ganzen Erde müßte Millionen von Pixeln breit sein. So könnte man eine riesige MIP-Map unseres Bildes der ganzen Erde mit einer Auflösung von sagen wir einem Meter erwägen. Kein Problem, oder? Aber ziemlich bald wirst Du bemerken, daß das eine 26 Ebenen tiefe Mip-Map-Pyramide erfordern würde, bei der das MIP-Level mit der höchsten Auflösung etwa 66 Millionen Pixel breit wäre. Das passt einfach auf keine 3D-Grafikkarte auf den Markt, zumindest nicht in diesem Jahrzehnt.
Ich schätze, Microsofts Virtual Earth kommt an diese Grenze, indem es seine riesige Erde-Textur in viele kleinere separate Kacheln von sagen wir 256 Pixeln Breite schneidet, von denen jede ihre eigene Mip-Map erhält. Dieser Ansatz würde bis zu einem gewissen Grad funktionieren, aber er wäre relativ langsam und ergebe einige der visuellen Artefakte, wie die Verschwommenheit, die wir oben sahen, und das Herein- und Heraus-Springen von großen quadratischen Bereichen beim Heran- und Heraus-Zoomen.
Bevor wir zum Kern der Sache kommen, ist ein letztes Konzept über die Mip-Maps zu verstehen. Stell Dir für einen Momentes vor, die Pixel der Mip-Map-Pyramide wären farbig unterlegt, wie ich bereits erwähnt habe, eine Ebene komplett Rot, eine andere Gelb usw… Malt man damit eine gekippte Fläche (wie die Ober-"Fläche" der Erde) erscheint es so, als würde die Pyramide in einem interessanten Winkel "angeschnitten", und nur die Teile der Pyramide benutzt, die für diese Ansicht erforderlich sind.
Es ist diese Eigenschaft von Mip-Mapping, die es Google Earth ermöglicht zu existieren, wie wir in einer Minute sehen werden.
 Ein typisches gekipptes Google Earth-Bild (Urheberrecht & Höflichkeit Google).
Ein typisches gekipptes Google Earth-Bild (Urheberrecht & Höflichkeit Google).
 Die gleiche Ansicht, unter Verwendung von Farbe, um zu zeigen, welche Mip-Ebene welches Pixel informiert
Die gleiche Ansicht, unter Verwendung von Farbe, um zu zeigen, welche Mip-Ebene welches Pixel informiertDas Beispiel auf der linken Seite zeigt eine normale 3D-Szene von Google Earth, und ein grobes Diagramm, das zeigt, wo ein 3D-Hardware-Systems das beste Quell-Pixel im Mip-Stapel finden könnte, wenn er wie gezeigt eingefärbt wäre.
Der nähere Bereich wird von der MIP-Ebene mit der höchsten Auflösung gefüllt (rot), und fällt auf immer niedrigere Auflösung zurück je weiter wir uns vom virtuellen Beobachtungs-Punkt entfernen. Das hilft Scintillation und andere Aliasing Probleme zu vermeiden, wie wir sie vorhin gesprochen haben und sieht ziemlich nett aus. Wir kommen so so nahe wie möglich zu einer 1:1-Entsprechung zwischen Quelle und Ziel, Pixel für Pixel, so daß Aliasing minimiert ist.
Sogar noch besser, tri-lineare Filterungs-3D-Grafik-Hardware wurde mit etwas verbessert, das sich anisotrope Filterung nennt (eine der Benutzer-Einstellungen in Google Earth), das ist im Wesentlichen die gleichen grundlegenden Idee wie die bisherigen Beispiele, aber mit nicht-quadratischen Filtern, was über die grundlegenden 2x2 hinaus geht. Dies ist sehr wichtig für die visuelle Qualität, weil die Hardware selbst mit dem fantastischen Mip-Mapping, um Szintillation auf der schmalen Achse zu vermeiden, eine Mip-Ebene mit niedriger Auflösung wählen muss, wenn Du ein strukturiertes Polygon in einen sehr schiefen Winkel kippst. Und das bedeutet, das gesamte Polygon wird zu geringen aufgelöst, wenn seine einzige Richtung erfordert, in die Kiste mit den niedrigen Auflösungen zu greifen. Überflüssig zu sagen, daß Du für die besten Ergebnisse anisotrope Filterung einschalten solltest, wenn das Deine Hardware unterstützt. Es ist jeden Cent wert.
Jetzt zum Kern der Sache
Wir haben nach wie vor das Problem zu lösen, wie eine Textur mit Millionen von Pixeln in beiden Richtungen "ge-mip-mapt" wird. Universal Textur (im Google Earth-Patent) löst das Problem und unterstützt dabei weiterhin Textur-Filterung in hoher Qualität. Es erzeugt eine riesige, Multi-Terabyte, virtuelle Textur der ganzen Erde auf eine extrem kluge Art. Ich kann das sagen, da ich es nicht wirklich erfand. Chris Tanner hat einen Weg heraus gefunden, auf Deinem PC das zu tun, was bisher ausschließlich auf teueren Grafik-Supercomputern mit kundenspezifischem Schaltkreis getan worden war, genannt Clip-Mapping (siehe SGI's PDF Papier, auch von Chris, Michael, et al., für viel mehr Details zu der ursprünglichen Implementierung in Hardware). Im Wesentlichen ist es diese Technologie, die Google Earth möglich macht. Mein erster Job in diesem Projekt war, das über eine Internetverbindung zum Laufen zu bringen und mich vorher nicht mehr blicken zu lassen.
Also, wie funktioniert es wirklich?
Nun, anstelle die riesige gesamte Erde-Textur auf einmal zu laden und zu zeichnen - was auf der meisten, aktuellen Hardware unmöglich ist - und anstatt sie in Millionen von Kacheln zu zerhacken und dadurch die gewünschte, bessere Filterung und Effizienz zu verlieren, erinnern wir uns an oben, daß wir zu einem bestimmten Zeitpunkt normalerweise nur eine schmale Scheibe oder Spalte unserer vollen Mip-Map-Pyramide benutzen. Der Winkel und die Höhe dieser virtuellen Spalte ändern sich ziemlich je nach unserer gegenwärtigen 3D-Perspektive. Diese Vorgehensweise ist einem klugen Algorithmus zum Berechnen oder Ableiten ziemlich direkt zugänglich, wenn bekannt ist, wo Du bist und was die Anwendung versucht zu zeichnen.
 Eine Universal Textur ist sowohl eine Mip-Map als auch ein Software emulierter Clip-Stack, das heißt sie kann ein MIP-Map mit viele mehr Ebenen und entschieden höherer Auflösung nachahmen, als sie in irgendeine reale Hardware paßt.Anmerkung: Obwohl dieses Diagramm es nicht so genau wie das Papier bildlich darstellt, der Clip-Stack "Winkel" verschiebt sich, um die Spalte möglichst zentriert zu halten.
Eine Universal Textur ist sowohl eine Mip-Map als auch ein Software emulierter Clip-Stack, das heißt sie kann ein MIP-Map mit viele mehr Ebenen und entschieden höherer Auflösung nachahmen, als sie in irgendeine reale Hardware paßt.Anmerkung: Obwohl dieses Diagramm es nicht so genau wie das Papier bildlich darstellt, der Clip-Stack "Winkel" verschiebt sich, um die Spalte möglichst zentriert zu halten.Also, dieser kluge Algorithmus findet heraus, welche Abschnitte der größeren virtuellen Textur zu einem bestimmten Zeitpunkt gerade gebraucht werden und bringt nur diese von System-Speicher in den speziellen Textur-Speicher Deiner Grafikkarte, von dem aus sie sehr effizient gezeichnet werden können, sogar in Echtzeit.
Aus der konzeptionellen Sicht ist die wichtigste Änderung zum grundlegenden Mip-Mapping, daß die verkehrt herume Pyramide nicht mehr nur eine Pyramide ist, sondern jetzt viel, viel höher ist, einen abgeschnittenen Stapel von Texturen enthält und seltsam genug, "Clip-Stack" genannt wird, vielleicht 16 bis 30+ Ebenen hoch. Konzeptionell ist das als hättest Du ein riesiges Mip-Map-Pyramide, die 16-30 Ebenen tief und Millionen und Milliarden Pixel breit ist, von der Du aber die Seiten abgeschnitten hast - d.h., die Teile, die Du im Augenblick nicht brauchst.
Stell’ Dir das Washington Monument auf den Kopf gestellt vor und Du erhältst die Idee. In der Tat, stell’ Dir diesen Turm zur einen oder anderen Seite geneigt vor, wie der in Pisa, und Du bis sogar genauer. Der Turm neigt sich so, daß die Pixel im Inneren des Turms die sind, die Du gerade jetzt zum Rendern brauchst. Der Rest wird ignoriert.
Jede Clip-Ebene hat nach wie vor die doppelt so hohe Auflösung wie die "unter" ihr, wie alle MIP-Maps und die nette Qualitäts-Filterung funktioniert noch wie vorher. Aber, da der Clip-Stack auf einen festen aber verschiebbaren Abdruck begrenzt wird, sagen wir 512x512 Pixel breit (eine weitere Benutzer-Einstellung von Google Earth), ergibt sich, daß jede Clip-Ebene sowohl die doppelte effektive Auflösung als auch das halbe Gebiet der vorherigen hat. Das ist genau das, was wir wollen. Wir bekommen alle Vorteile einer riesigen Mip-Map, mit nur den Teilen, die zu jeder gegebenen Ansicht relevant sind.
Oder anders herum, Google Earth lädt geschickt und schrittweise Informationen mit hoher Auflösung für das, was im Brennpunktbereich Deiner Ansicht ist (der rote Teil oben) und die Auflösung verringert sich von dort mit den Potenzen von zwei. Während Du das Land kippst, über es fliegst und siehst wie es zum Horizont läuft, sendet Universal Textur immer optimal nur die besten und nützlichsten Detail-Niveaus zur Hardware. Was nicht benötigt wird, wird nicht einmal berührt. Das ist eins der Dinge, die es ultra-effizient macht.
Es ist auch sehr Speicher-effizient. Der gesamte Speicher für eine Textur so groß wie die Erde, braucht jetzt (diese 512 breite Basis-Mip-Map und, sagen wir, 20 zusätzlichen Clip-Levels für Daten angenommen) nur etwa 17 Megabyte, nicht die Dutzende und Hunderte von Terabytes von denen wir vorher bedroht wurden. Es ist tatsächlich machbar, und funktionierte 1999 auf 3D-Hardware, die nur 32 MB oder weniger hatte. Andere Techniken sind erst jetzt möglich, mit immer größeren 3D-Karten.
In der Tat, mit nur 20 Clip-Ebenen (plus 9 Mip Ebenen für die Basis Pyramide), sehen wir, daß 229 eine virtuelle Struktur ergibt, die für bis zu 536 Millionen Pixel in beiden Dimension ausreicht. Multipliziere das vertikal mit 1/2, das ergibt ein virtuelles Bild mit einigen hundert Terapixels im der Fläche oder genügend Reserven, um Eigenschaften darzustellen, die so klein sind wie 0,15 Meter (ungefähr 5 Zoll), soweit die Daten vorhanden sind. Und das ist nicht die tatsächliche Grenze. Ich wählte einfach 20 Clip-Levels als angemessene Zahl aus. Und Du dachtest, das Rennen nach mehr Megapixels in digitalen Kameras wäre eine große Herausforderung. Multipliziere das mit einer Million und Du bist im planetarischen Murmelspiel.
Glücklicherweise muß Google fürs Erste in Wirklichkeit nur einige Dutzend Terapixels Bilder speichern. Die andere Schönheit des Systems ist, daß die höchsten Auflösungs-Niveaus nicht überall zu existieren brauchen, damit es funktioniert. Überall dort, wo die Auflösung eher begrenzt ist, wo noch Lücken, fehlende Daten, etc.. sind, zeichnet das System nur das, was es hat. Wenn Daten mit höhere Auflösung verfügbar sind, werden sie auch abgeholt und gezeichnet. Wenn nicht, verwendet das System diese Daten in der Version mit der nächst niedrigeren Auflösung (siehe Mip-Mapping oben) bevor es Nichts zeichnet. Das ist genau, warum Du in einige Bereiche zoomen kannst und nur große Unschärfe siehst, während andere Bereiche hübsch und knackig sind. Es hängt alles von der Verfügbarkeit von Daten ab. Das 3D-Rendern gibt hier überhaupt keine harte Grenze vor. Wenn die Daten verfügbar wären, könntest Du eine Zentimeter-Auflösung in der Mitte des Ozeans sehen .
Der Schlüssel, damit das allen funktioniert, während Du auf der 3D-Erde umherwanderst, ist, daß das System effizient neue Textur-Daten von Deinem lokalen Festplatte-Cache und System-Speicher in Deinen Grafik-Textur-Speicher übertragen kann. (Beim nächsten Mal werden wir mit abdecken, wie die Sachen in Deinen lokalen Cache kommen). Du hast sicher schon gesehen, wie das Nachladen der Textur geschieht, vielleicht aber ohne es wahrzunehmen. Hoffentlich schätzt Du jetzt die ganze, harte Arbeit, die notwendig war, damit das alles so glatt funktioniert. - es ist, wie einen ganzen Planeten Stückchenweise durch einen Strohhalm zu füttern.
Bevor wir weiter machen, gibt's noch eine interessante Sache. Der Grund, warum dieses Patent asynchrone Verhalten betont, ist, daß diese Textur Bits eine kurze aber sich auf summierende Zeit brauchen, um fortwährend auf Deine 3D-Hardware hoch geladen zu werden. Und diese Zeit wird weggenommen vom glatten und jitter-freien Zeichen der 3D-Bilder oder einfach dem Abarbeiten der Benutzer-Eingabe - ganz zu schweigen davon, daß die Hardware gewöhnlich mit ihrem eigenen anspruchsvollem Zeitplan beschäftigt ist.
Um auf der meisten Hardware gleich bleibend 60 Bilder pro Sekunde zu erreichen, wird das Hochladen der Textur in kleine, dünne Scheiben aufgeteilt, die sehr schnell den Grafik-Video-Speicher mit den passenden Quell-Daten aktualisieren, welchen Bereich Du auch immer gerade ansiehst; hoffentlich, kurz bevor Du ihn brauchst, aber schlimmstenfalls, gleich danach. Was wirklich klug ist, daß das System nur den kleinsten Teile der benötigten Texturen hochzuladen braucht, und es tut es, ohne jemanden warten zu lassen. Das bedeutet, das Rendering kann so glatt und die Benutzerschnittstelle so flüssig wie möglich sein. Ohne diese Asynchronität, vergess' diese netten, parabolischen Bögen von Küste zu Küste.
Nun, auch andere virtuelle Globen können die Textur der ganzen Erde virtualisieren, vielleicht schneiden sie sie in Kacheln, und benutzen sogar mehrfache Potenzen-von-2-Auflösungen, wie es GE tut. Aber ohne eine Universal-Texturing-Komponente oder etwas besserem, werden sie entweder auf 2D-top-down-Rendering begrenzt sein, oder sie machen 3D-Rendering mit unbefriedigendem Ergebnis, Verschwommenheit, Szintillation und nicht annähernd so gutem Durchsatz beim Übertragen der Daten vom Pufferspeicher in den Textur-Rendern-Speicher.
Und das ist wahrscheinlich mehr, als Du jemals davon wissen wolltest, wie die gesamte Erde auf Deinen Schirm gezeichnet wird, Pixel für Pixel.
Ich werde hier fürs Erste enden und beim nächsten Mal fortfahren mit dem 2. Patent zum Übertragen von Daten, um darüber zu sprechen, wie Google Earth die Daten auf Deinen Computer bringt.
Für öffentliche Kommentare zu meiner Übersetzung kann sehr gerne mein Gästebuch benutzt werden.
Die folgenden Google™ SketchUp-(3D-)Modelle habe ich (für Google™ Earth) veröffentlicht:
- Rosneggerstraße 3, Radolfzell:
für Google™ Earth,
für Google™ SketchUp
(Google™ 3D-Galerie: http://sketchup.google.com/3dwarehouse/details?mid=4310e1617463dad9575358a9fc3700f2)
- vhs Radolfzell
(ohne Textur):
Für Google™ Earth,
für Google™ SketchUp
(Google™ 3D-Galerie: http://sketchup.google.com/3dwarehouse/details?mid=5a0cfe20bf65b54b44adfc0aa013be36)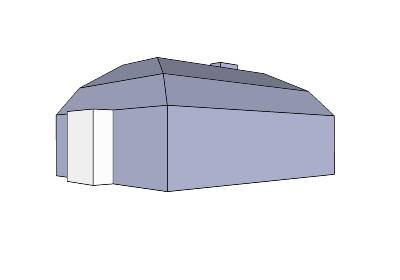
- vhs Konstanz
(ohne Textur):
Für Google™ Earth,
für Google™ SketchUp
(Google™ 3D-Galerie: http://sketchup.google.com/3dwarehouse/details?mid=601e7ecc881e0bf034687b4656183fdc)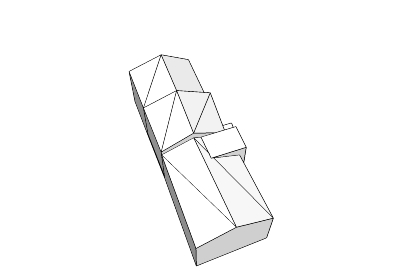
Die folgenden Fotos habe ich in Panoramio (für Google™ Earth) veröffentlicht:
- Das ehemalige Verwaltungsgebäude der vhs Radolfzell: Im jpg-Format, im Google Earth-Format
(In Panoramio: http://www.panoramio.com/photo/1245270)
___
"Google" ist ein Markenzeichen der Google Inc., 1600 Amphitheatre Parkway, Mountain View, CA 94043, USA